Contents
Well if you are on this post, it’s likely you are considering AWS Redshift for your use case or are currently leveraging it. AWS was the leader in the 2021 Gartner Magic Quadrant for Cloud Database Management Systems. AWS Redshift is one of the most popular and widely used Cloud Data Warehouses as it can handle petabyte-scale workloads. You can leverage the traditional SQL to query a huge volume of Structured & Semi-Structured Data in your Database, Data Warehouse, and Data Lake. Moreover, AWS Redshift offers Big Data Analytics and Machine Learning approaches to further aggregate data.
Let’s discover some of the remarkable features AWS Redshift has to offer, that you should consider before choosing it for your use case.
1) Scalable Columnar Storage
In a traditional relational database table, each row represents a single record with its field values. Data blocks in a row-wise database store value sequentially for each subsequent column that makes up the complete row. On the other hand, each data block in columnar storage holds the values of a single column for many rows. Amazon Redshift seamlessly transforms data to columnar storage for each of the columns when records enter the system, as demonstrated below.
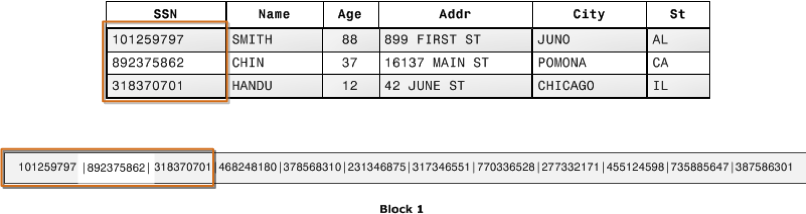
While a relational database is designed to store rows of data and is commonly used in transactional applications, the AWS Redshift columnar database is designed to get data in columns quickly and is commonly used in analytical applications. AWS Redshift Columnar storage increases analytic query speed by decreasing the overall disc I/O needs and increasing throughput.
2) Robust Massively Parallel Processing
Massively Parallel Processing (MPP) is a distributed design solution to massive data operations in which numerous processors use a “Divide & Conquer” method. A huge processing work is divided into smaller pieces and distributed across a group of processors. The processors work in parallel rather than sequentially to perform their computations. The result is a significant decrease in time. Hence, it takes Redshift to finish a single, big assignment quickly as compared to traditional Data Warehouses. In addition to queries, the MPP design allows for concurrent data loading, backups, & restorations. The Redshift architecture is naturally parallel, thus load distribution for end-users requires no further tweaking or overhead.
3) Powerful Advanced Query Accelerator (AQUA)
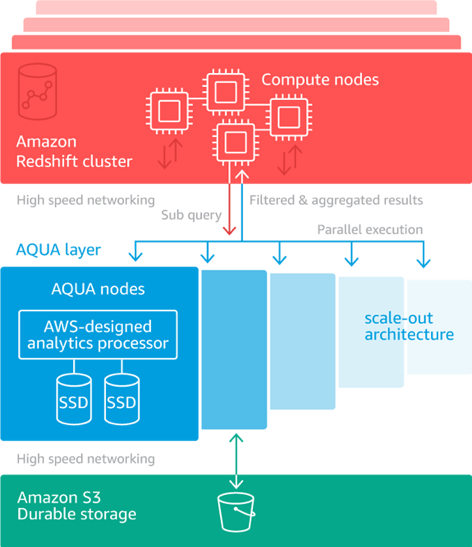
Over several years, as existing Data Warehouses with centralized storage expand, the network bandwidth required to transmit all data becomes a bottleneck for query performance. But, when it comes to AWS Redshift, AQUA offers a fresh approach. It’s a distributed, hardware-accelerated cache that helps AWS Redshift operate up to 10x quicker than other Cloud Data Warehouses by automatically enhancing specific sorts of queries.
AQUA accelerates your queries by:
- Running data-intensive operations like scanning, filtering, and aggregation closer to the storage layer. This helps to remove superfluous data transit between data storage and compute clusters, thereby, avoiding any networking bandwidth limits.
- Using bespoke Analytics processors built on FPGAs to speed up tasks, as well as using AWS Nitro chips tailored to speed up data encryption and compression.
- Parallel Processing of large volumes of data across numerous nodes, and dynamically scaling out capacity as your storage demands expand.
4) Flexible Pricing Plans
AWS Redshift offers diverse yet flexible pricing plans. The pricing for a terabyte of data starts at $0.25/hour and maybe ramped up from there. To begin, you select the type of node you wish to use. AWS Redshift offers 3 types of nodes – RA3 nodes with managed storage, DC2 nodes, & DS2 nodes. A sample AWS Redshift pricing plan based on the node selected for the Asia Pacific (Mumbai) Region is displayed below:
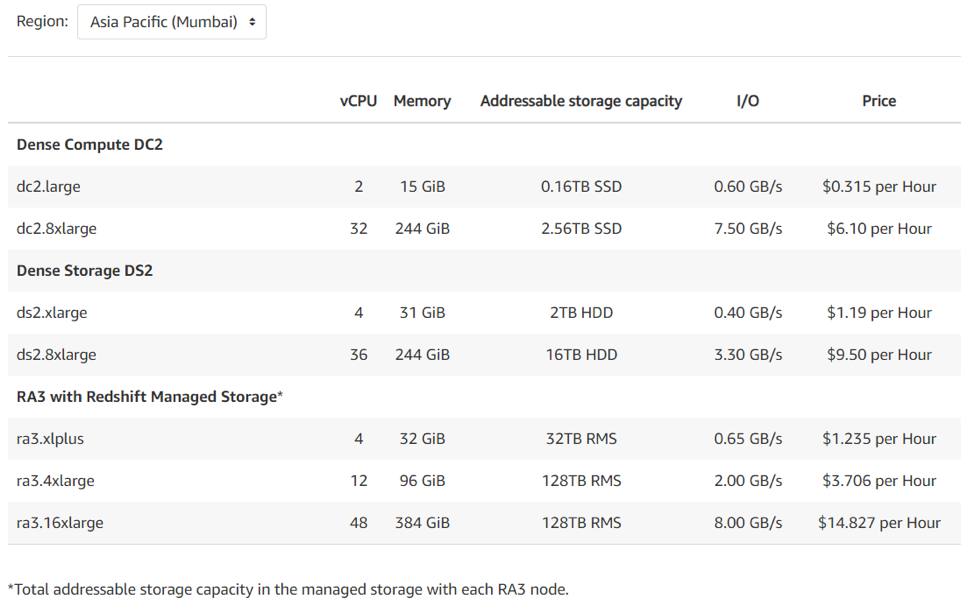
Redshift also offers a pay-as-you-go pricing plan based on your requirements as detailed below:
- AWS Redshift Node Types: With AWS Redshift on-demand pricing, you can choose the optimum cluster configuration and node type for your requirements and pay for capacity by the hour. You can leverage the pause and resume functionality to suspend on-demand pricing while a cluster is not in use. For steady-state workloads, Reserved Instances can be used instead of on-demand instances, resulting in considerable discounts over on-demand pricing.
- AWS Redshift Spectrum Pricing: In this type of pricing plan, you only pay for the number of bytes scanned when you run SQL queries directly on the data in your Amazon S3 Data Lake. Data Definition Language (DDL) commands for managing partitions and unsuccessful queries, such as CREATE/ALTER/DROP TABLE, are free of charge.
- Concurrency Scaling Pricing: Each cluster receives up to 1 hour of free Concurrency Scaling credits each day, which is enough for 97% of clients. Even with thousands of concurrent queries & users, you’ll be able to deliver consistently fast performance. For usage that surpasses the free credits, you just pay a per-second on-demand cost. The per-second on-demand rate is determined by the cluster type and number of nodes.
- RMS Pricing: You only pay for the data you store in RA3 clusters, regardless of how many compute nodes you use. You just pay for the total quantity of data in managed storage on an hourly basis.
- Redshift ML Pricing: If you haven’t used Amazon SageMaker before, you’ll be eligible for the free tier when you start using Redshift ML. This offers 2 free CREATE MODEL requests per month for 2 months, with each request containing up to 100,000 cells. Your free tier begins the first month after you generate your first Redshift ML model.
You can explore the AWS Redshift pricing details on the AWS Redshift pricing page.
5) Multifarious Integrations
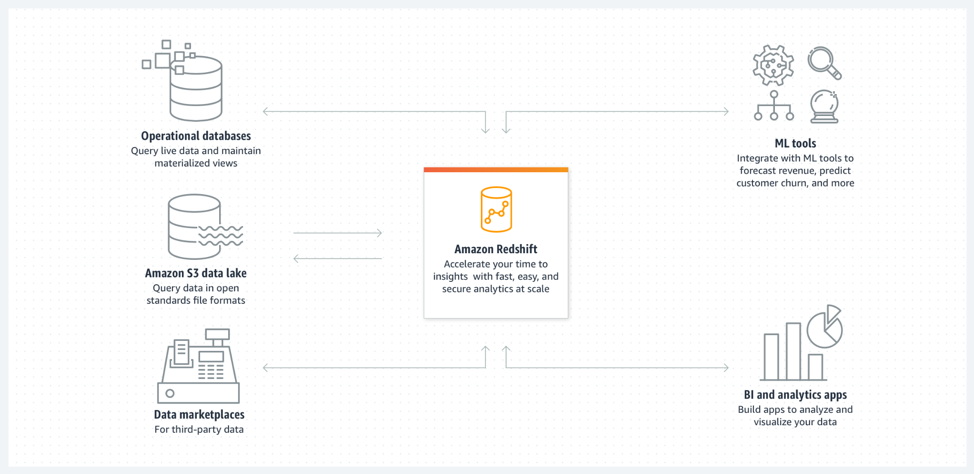
Working with industry-leading tools and professionals for loading, manipulating, and visualizing data can help you optimize and enhance your AWS Redshift. Many organizations currently use AWS for their infrastructure, including AWS Elastic Compute Cloud(EC2) for servers, AWS Simple Storage Service(S3) for long-term storage, & AWS Relational Database Service(RDS) for databases, including other AWS services. If the rest of your infrastructure is already on AWS, Redshift works great since you receive the benefit of data proximity and the cost of data transit is quite modest. Moreover, S3 has become the de-facto Cloud storage choice for many enterprises. Hence, pairing S3 with AWS Redshift can help you ease your workflows.
AWS Redshift is accessible using standard JDBC and ODBC drivers and runs on industry-standard SQL. You can leverage any ETL, SQL, or Business Intelligence (BI) tool that you’re familiar with. AWS Redshift has verified integrations with leading BI and ETL providers, with many of them giving free trials to get you started importing and analyzing your data. You can also go to the AWS Marketplace to deploy and configure Amazon Redshift-compatible solutions in minutes.
6) End-to-End Data Encryption
Data privacy and security requirements are critical and unique to each organization. AWS Redshift, like all other AWS services, comes with a variety of security protections. It supports IAM roles that can be used to maintain access control at the account level. Using this you can configure Redshift database groups and users and restrict access to certain databases and tables.
AWS Redshift’s Encryption options are extensive and extremely flexible. Hence, users can choose the encryption standard that best suits their needs. It also supports Data Encryption for all data kept in the cluster, as well as SSL Data Encryption in transit. The following are some of the security Encryption options available in AWS Redshift:
- The ability to use either an AWS-managed key or a customer-managed key.
- Data migration between encrypted and non-encrypted clusters.
- Options for AWS Key Management Service or HSM (Hardware Security Module).
- Depending on the situation, you can use single or double encryption.
You can read more about other AWS Redshift security and encryption techniques here.
7) Advanced Analytics & Machine Learning
Regardless of your workloads or concurrent use, AWS Redshift leverages Machine Learning (ML) to deliver great performance. Redshift uses advanced algorithms to forecast the run durations of incoming queries and allocates them to the most efficient queue for processing. For deeper analysis and robust ML models, you can additionally leverage the following powerful services offered by AWS Redshift:
- AWS Redshift ML: Data & BI professionals can use Redshift ML to design, train, and deploy Amazon SageMaker models using SQL. Since Redshift ML supports standard SQL, it’s simple to experiment with new use cases for your Analytics data. It supports Bring Your Own Model (BYOM) for local or remote inference.
- AWS Redshift Query Editor V2: It’s a web-based SQL client application for writing and running queries in your AWS Redshift. You can use charts to view query results as well as can share queries with your team. Query Editor V2 allows you to explore, build schemas and tables, import data, and author SQL queries, stored procedures, and UDFs. It enables Data Analysts to use an IAM role for READ, WRITE, or ADMIN access on the AWS Redshift cluster without requiring any additional admin rights.
8) AWS Redshift Serverless
AWS Redshift Serverless (Preview) is an alternative that allows you to perform and scale Analytics in seconds without having to set up or manage Data Warehouse Infrastructure. By effortlessly loading and querying data in the Data Warehouse, users can get insights easily.
Given below are some of the advantages of using AWS Redshift Serverless:
- Quickly get insights without having to provision and manage clusters.
- Intelligent & automated scaling depending on workload demands, without the need to over-provision resources.
- Scalability & version update services available at all times.
- Fast query performance without the need for database tuning.
- Valuable SQL analytics, durability, and transactional guarantees.
- Reduced Data Warehouse complexity & increased cost efficiency by paying for used capacity only.
Therefore, selecting the right Data Warehouse is a crucial step, as it involves a lot of time and effort. Keeping the above points into consideration while choosing AWS Redshift will help make your decision easier.
Conclusion
In a nutshell, this post listed some of the noteworthy points you need to keep in mind while choosing AWS Redshift. Want to explore other features and use cases of AWS Redshift? You can give a read to AWS Redshift 101 and Amazon Redshift FAQs.