Contents
An increasing number of data sources, formats, and technologies continue to make it difficult to aggregate all the data and make sense of it. Nevertheless, modern organizations leave no stone unturned when it comes to collecting and using data – given how important it is to create a sustainable competitive advantage.Integrating large volumes of data from these disparate sources requires a proper infrastructure in place, and this is where the ETL process becomes important.
What is ETL?
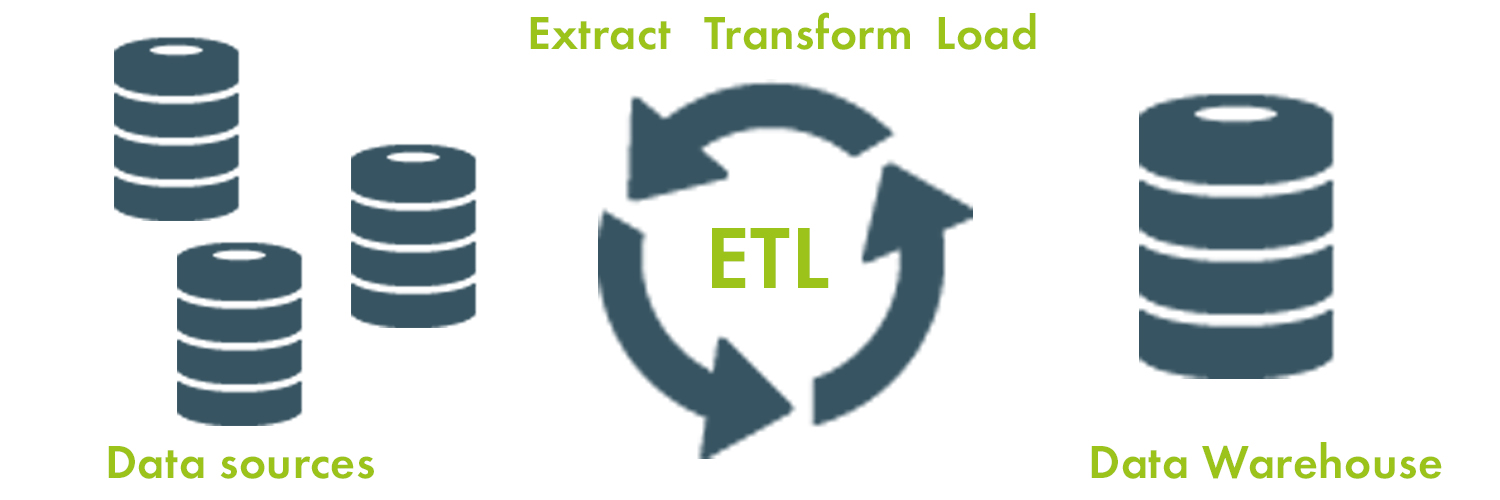
ETL stands for Extract, Transform and Load. The process involves transporting data from a data source to a data repository such as a data lake or a data warehouse. The fact that data from these sources tends to be in different formats, it needs to be transformed into the required format before it can be loaded into a data warehouse for analysis.
The ETL process
As noted, the ETL process includes three major steps: Extraction, Transformation, and Loading. However, each of these steps may include further processes depending on business requirements.
Let us now dive deeper to understand how ETL can be used for transforming raw data into insights:
Extraction
Typically, some companies rely on data from a single source, or a few data sources where data is formatted in the same way. However, most organizations have data coming in from a variety of disparate sources. This means that the data can be both, structured and unstructured. As the first step of the ETL process, data extraction is used to import and compile data from these sources before it can be transformed or loaded into a data warehouse.
Once the data is compiled, it needs a certain level of consistency before it can be transformed. While this is something that can be done manually via coding, it is important to note that this can be very tedious and time-consuming, especially if the incoming data is of very large size. Therefore, to save time, money and effort, organizations take advantage of ETL tools to automate the data extraction process and create workflows that are efficient and reliable.
To sum up, data extraction is often a two-step process: importing and compiling data and preparing it before it can be transformed.
Transformation
As soon as the data is extracted from the data sources, rules, regulations, and checks can be applied to ensure that the data quality is not compromised before it is loaded. In other words, it can be transformed to match the target system requirements. This is the second step of the ETL process and is called transformation.
Data transformation can often include sub-processes like data conversion to meet business requirements, data standardization to format the entire data as per the target system’s standard format, data cleansing, filtering, deduplication, and sorting, where necessary.
Transformation is typically the most critical step of the entire ETL process since it enhances data integrity and ensures that the data is fully compatible with the target system and ready for analytics.
Loading
As discussed previously, before it can be loaded into the target system, data is transformed in a staging area. Once the data is transformed, it is ready to be loaded into the target system such as a data warehouse. This is the final stage in the ETL process.
Data can be loaded in two ways depending on the organization’s ability to maintain large data sets. Full loading allows to load the entire data into unique records in the data warehouse. On the other hand, incremental loading compares the data to be loaded with data already stored in the target system and loads data only if new or unique records are found.
The importance of ETL for businesses
As previously mentioned, writing code to extract, transform and load data can easily become tedious, time-consuming, and expensive, especially if there is a large amount of data. This is arguably one of the most important reasons why businesses of all sizes are automating their data pipelines using ETL tools. Having said that, there is certainly more to it than meets the eye:
Single source of truth
ETL integrates data from various sources and presents a unified view, or a single source of truth, to base business decisions on.
Maintaining historical data
ETL allows to consolidate historical data with data coming in from newer data sources. This makes the data analysis more comprehensive and complete.
Improving efficiency
Having multiple data sources means that organizations not only have to deal with data of different formats, but also a whole lot of it. This only creates operational inefficiencies and delays because manually dealing with data extraction, transformation and loading can take a lot of time and effort.
To wrap up, ETL is a three-step process that involves data extraction, transformation, and loading. The process allows organizations to integrate data and present a unified view for business decisions. While ETL can be carried out manually, it is tedious and time-consuming. Most organizations use ETL tools and automate the entire process to save on costs associated with resources.